
StackExchange.Redis跑起来,为什么这么溜? StackExchange. StackExchange Exchange. 为什么这么溜 Stack Redis 跑起来
StackExchange.Redis 是一个高性能的 Redis 客户端库,主要用于 .NET 环境下与 Redis 服务器进行通信,大名鼎鼎的stackoverflow 网站就使用它。它使用异步编程模型,能够高效处理大量请求。支持 Redis 的绝大部分功能,包括发布/订阅、事务、Lua 脚本等。由 StackExchange 团队维护,质量和更新频率有保障。这篇文章就来给大家分享下 StackExchange.Redis 为什么玩的这么溜。
我将通过分析 StackExchange.Redis 中的同步调用和异步调用逻辑,来给大家一步步揭开它的神秘面纱。
同步API
向Redis发送消息
Redis 客户端的 Get、Set 等操作都会封装成为 Message,操作最终会走到这个方法,我们先大致看下代码:
ConnectionMultiplexer.cs
internal T? ExecuteSyncImpl<T>(Message message, ResultProcessor<T>? processor, ServerEndPoint? server, T? defaultValue = default)
{
...
// 创建一个ResultBox对象,这个对象将会放到Message中用来承载Redis的返回值
var source = SimpleResultBox<T>.Get();
WriteResult result;
// 锁住ResultBox对象,下边会有大用
lock (source)
{
// 将Message发送到Redis服务器
result = TryPushMessageToBridgeSync(message, processor, source, ref server);
...
// 调用 Monitor.Wait 释放对 ResultBox 对象的锁,同时让当前线程停在这里
if (Monitor.Wait(source, TimeoutMilliseconds))
{
Trace("Timely response to " + message);
}
...
}
// 最终从 ResultBox 取出结果
var val = source.GetResult(out var ex, canRecycle: true);
...
return val;
...
}仔细说一下大概的处理逻辑。
- 先构造一个ResultBox对象,用来承载Message的执行结果。
- 然后尝试把这个Message推送到Redis服务器,注意程序内部会把当前Message和ResultBox做一个绑定。
- 等待Redis服务器返回,返回结果赋值到ResultBox对象上。
- 最后从ResultBox对象中取出结果,返回给调用方。
注意这里用到了锁(lock),还使用了Monitor.Wait,这是什么目的呢?
Monitor.Wait 一般和 Monitor.Pulse 搭配使用,用来在线程间通信。
- 调用 Monitor.Wait 时,lock住的ResultBox会被释放,同时当前线程就会挂起,停在这里。
- Redis服务器返回结果后,把结果数据赋值到ResultBox上。
- 其它线程lock住这个ResultBox,调用Monitor.Pulse,之前被挂起的线程继续执行。
通过这种方式,我们就达成了一个跨线程的同步调用效果。
为什么会跨线程呢?直接调用Redis等着返回结果不行吗?
因为 StackExchange.Redis 底层使用了 System.IO.Pipelines 来优化网络IO,这个库采用了生产者/消费者的异步模式来处理网络请求和响应,发送数据和接收数据很可能是在不同的线程中。
以上就是向Redis服务器发送消息的一个宏观理解,但是这里有一个隐藏的问题:
异步情况下怎么把Redis的返回结果和消息对应上?
我们继续跟踪向 Redis 服务器发送 Message 的代码,也就是深入 TryPushMessageToBridgeSync 的内部。
一路跟随,代码会走到这里:
PhysicalBridge.cs
internal WriteResult WriteMessageTakingWriteLockSync(PhysicalConnection physical, Message message)
{
...
bool gotLock = false;
try
{
...
// 获取单写锁,同时只能写一个Message
gotLock = _singleWriterMutex.Wait(0);
if (!gotLock)
{
gotLock = _singleWriterMutex.Wait(TimeoutMilliseconds);
if (!gotLock) return TimedOutBeforeWrite(message);
}
...
// 继续调用内部方法写数据
WriteMessageInsideLock(physical, message);
...
// 刷新网络管道,将数据通过网络发出去
physical.FlushSync(false, TimeoutMilliseconds);
}
catch (Exception ex) { ... }
finally
{
if (gotLock)
{
_singleWriterMutex.Release();
}
}
}这里边用信号量做了一个锁,保证同时只有一个写操作。
那么为什么要保证同时只能一个写操作呢?
我们继续跟踪代码:
private WriteResult WriteMessageToServerInsideWriteLock(PhysicalConnection connection, Message message)
{
...
// 把消息添加到队列
connection.EnqueueInsideWriteLock(message);
// 把消息写到网络接口
message.WriteTo(connection);
...
}这里有两个操作,一是将Message添加到队列,二是向网络接口写数据。
保证同时只有一个写操作,或者加锁的目的,就是让它俩一起完成,能对应起来,不会错乱。
那么我们还要继续问:写队列和写网络对应起来有什么用?
这个问题不好回答,我们先来看看这两个操作都是干什么用的?
为什么要把Message写入队列?
同步IO可以直接拿到当前消息的返回结果,但是 System.IO.Pipelines 底层是异步操作,当处理结果从Redis返回时,我们需要把它对应到一个Messge上。加入队列就是为了方便找到对应的消息。至于为什么用队列,而不用集合,因为队列能够很好的满足这个需求,下边会有说明。
写队列代码在这里:
PhysicalConnection.cs
internal void EnqueueInsideWriteLock(Message next)
{
...
bool wasEmpty;
lock (_writtenAwaitingResponse)
{
...
_writtenAwaitingResponse.Enqueue(next);
}
...
}入队列需要先加锁,因为可能是多线程环境下操作,Queue自身不是线程安全的。
再看一下把消息写到网络接口,这个的目的就是把消息发送到Redis服务器,看一下代码:
PhysicalConnection.cs
internal static void WriteUnifiedPrefixedString(PipeWriter? maybeNullWriter, byte[]? prefix, string? value)
{
...
// writer 就是管道的写入接口
var span = writer.GetSpan(3 + Format.MaxInt32TextLen);
span[0] = (byte)'$';
int bytes = WriteRaw(span, totalLength, offset: 1);
writer.Advance(bytes);
if (prefixLength != 0) writer.Write(prefix);
if (encodedLength != 0) WriteRaw(writer, value, encodedLength);
WriteCrlf(writer);
...
}源码最底层是通过 System.IO.Pipelines 中的 PipeWriter 把 Message 命令发送到Redis服务器的,这段代码比较复杂,大家先大概知道做什么用的就行了。
到此,向Redis发送消息就处理完成了。
现在我们已经大概了解向Redis服务器发送消息的过程:在最上层通过Monitor模拟了同步操作,在最底层使用了高效的异步IO,为了适配同步和异步,写操作内含了两个子操作:写队列和写网络。
但是我们仍然不能回答一个问题:写队列和写网络为什么要放到一个锁中执行?或者说为什么要保证同时只能一个写操作?
要回答这个问题,我们还得继续看程序对Redis响应结果的处理。
处理Redis响应结果
Redis 客户端与 Redis 服务器建立连接时,会创建一个死循环,持续的从 System.IO.Pipelines 的管道中读取Redis 服务器返回的消息,并进行相应的处理。最上层方法就是这个 ReadFromPipe:
PhysicalConnection.cs
private async Task ReadFromPipe()
{
...
while (true)
{
...
// 没有新数据从Redis服务器返回时,ReadAsync会等在这里
readResult = await input.ReadAsync().ForAwait();
...
var buffer = readResult.Buffer;
...
if (!buffer.IsEmpty)
{
// 这里边解析数据,并赋值到相关对象上
handled = ProcessBuffer(ref buffer);
}
}
}对返回数据的处理重点在这个 ProcessBuffer 方法中。它会先对数据进行一个简单的解析,然后再调用 MatchResult,从字面义上看就是匹配结果,匹配到那个结果呢?
private int ProcessBuffer(ref ReadOnlySequence<byte> buffer)
{
...
var reader = new BufferReader(buffer);
var result = TryParseResult(_protocol >= RedisProtocol.Resp3, _arena, in buffer, ref reader, IncludeDetailInExceptions, this);
...
MatchResult(result);
...
}还记得我们在上边向Redis发送Message前,先创建了一个 ResultBox 对象,匹配的就是它。
怎么找到对应的 ResultBox 对象呢?
看下边的代码,程序从队列中取出了一个Message 实例,就是要匹配到这个 Message 实例关联的ResultBox。
private void MatchResult(in RawResult result)
{
...
// 从队列中取出最早的一条Redis操作消息
lock (_writtenAwaitingResponse)
{
if (!_writtenAwaitingResponse.TryDequeue(out msg))
{
throw new InvalidOperationException("Received response with no message waiting: " + result.ToString());
}
}
...
// 将Redis返回的结果设置到取出的消息中
if (msg.ComputeResult(this, result))
{
_readStatus = msg.ResultBoxIsAsync ? ReadStatus.CompletePendingMessageAsync : ReadStatus.CompletePendingMessageSync;
// 完成Redis操作
msg.Complete();
}
...
}为什么从队列取出的 Message 就一定能对应到 Redis 服务器当前返回的结果呢?
要破案了,还记得上边的那个未解问题吗:为什么要保证同时只能一个写操作?
我们每次操作Redis都是:先把Message压入队列,然后再发送到Redis服务器,这两个操作紧密的绑定在一起;而Redis服务器是单线程顺序处理的,最先返回的就是最早压入队列的。加上每次只有一个写操作的控制,我们就能保证最先写入队列的(也就是最先发到Redis服务器的)Message,就能对应到最先从Redis服务器返回的数据。
上面这段程序中的 msg.ComputeResult 就是用来将 Redis 最新返回的数据赋值到最新从队列中拿出来的 Message 实例中。
现在 Message 实例 已经获取到了 Redis返回结果,还记得之前的发送线程一直在挂起等待吗?
下边的 msg.Complete 就是来让发送线程恢复执行的,看这个代码 :
Message.cs(Message)
public void Complete()
{
...
// ResultBox激活继续处理
currBox?.ActivateContinuations();
}还有一层封装,继续看这个代码:
ResultBox.cs(SimpleResultBox)。
void IResultBox.ActivateContinuations()
{
lock (this)
{
// 通知等待Redis响应的线程,Redis返回结果了,请继续你的表演
Monitor.PulseAll(this);
}
...
}Monitor.PulseAll 一出,发送线程立马恢复执行,向调用方返回执行结果。
一次同步调用就这样完成了。
异步API
异步API和同步API使用相同的通信底层,包括写队列和写网络管道的处理,只是在处理返回值的方式上存在不同。大家可以看一下异步和同步调试堆栈的对比图:
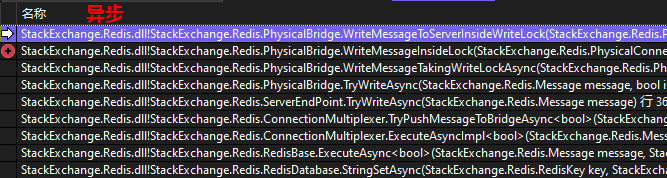
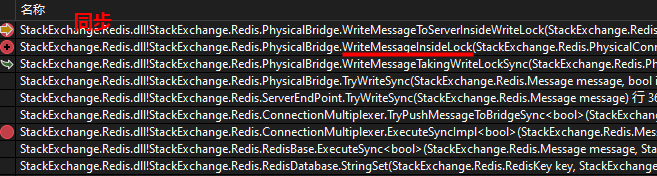
执行到 PhysicalBridge.WriteMessageInsideLock 这一步时处理就同步了。这一步的代码上边也贴过了,这里再给大家看看:其中的主要逻辑就是写队列和写网络管道。
private WriteResult WriteMessageToServerInsideWriteLock(PhysicalConnection connection, Message message)
{
...
// 把消息添加到队列
connection.EnqueueInsideWriteLock(message);
// 把消息写到网络接口
message.WriteTo(connection);
...
}向Redis发送消息
我们再简单看看异步API中是如何发送消息的,看代码:
internal Task<T?> ExecuteAsyncImpl<T>(Message? message, ResultProcessor<T>? processor, object? state, ServerEndPoint? server)
{
...
// 创建一个Task执行状态跟踪对象
TaskCompletionSource<T?>? tcs = null;
// 创建一个ResultBox对象,这个对象将会放到Message中用来承载Redis的返回值
// 异步这里特别将 ResultBox 和 TaskCompletionSource 绑定到了一起
// 获取到Redis服务器返回的数据后,TaskCompletionSource 的执行状态将被更新为完成
IResultBox<T?>? source = null;
if (!message.IsFireAndForget)
{
source = TaskResultBox<T?>.Create(out tcs, state);
}
// 将Message消息发送到 Redis服务器
var write = TryPushMessageToBridgeAsync(message, processor, source!, ref server);
...
// 返回Task,调用方可以 await
return tcs.Task;
}相比同步API,这里多创建了一个 TaskCompletionSource 的实例,它用来跟踪异步任务的执行状态,程序会在接收到Redis服务器的返回数据时,将 TaskCompletionSource 的状态更新为完成执行。
里边的代码我就不展开讲了,大家有兴趣的可以按照上方我截图的调用堆栈去跟踪下。
处理Redis响应结果
异步API和同步API使用同一个死循环方法:ReadFromPipe,程序启动时也只有这一个死循环在运行。
代码上边都讲过了,这里只说下最后“ResultBox激活继续处理”的部分,这个 ResultBox 和同步调用的 ResultBox 略有不同,看代码:
void IResultBox.ActivateContinuations()
{
...
ActivateContinuationsImpl();
}
private void ActivateContinuationsImpl()
{
var val = _value;
...
TrySetResult(val);
...
}
public bool TrySetResult(TResult result)
{
// 设置异步任务执行完成
bool rval = _task.TrySetResult(result);
...
return rval;
}最重要的就是 _task.TrySetResult 这句,这里的 _task 就是发起异步调用时创建的 TaskCompletionSource 实例,TrySetResult 的作用就是设置异步任务执行完成,对应的 await 代码就可以继续向下执行了。
await client.SetAsync("hello", "fireflysoft.net");
// 继续执行下边的代码
...总结
总体执行逻辑
通过对同步API、异步API的执行逻辑分析,我这里总结了一张图,可以让大家快速的理清其中的处理逻辑。
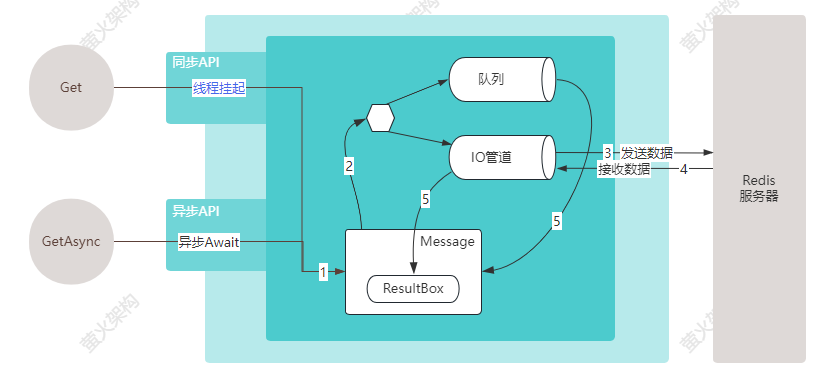
我再用文字描述下这个执行逻辑:
1、无论是同步调用还是异步调用,StackExchange.Redis 底层都是先会创建一个 Message 对象;每个 Message 对象都会关联一个ResultBox对象(同步和异步调用对应的ResultBox对象略有不同),这个对象用来承载Redis执行结果;
2、然后程序会把Message存入队列、发送到网络IO管道,写队列和写网络IO放到了一个互斥锁中,同时只有一个Message写入,这是为了保证收到Redis响应时正好对应队列中的第一条数据。
执行完这些操作后,API会等待,但是同步调用和异步调用等待的方式不同,同步会挂起线程等待其它线程同步结果,异步会使用await等待Task执行结果;
3、Redis 命令被发送到网络,抵达Redis服务器
4、接收到Redis服务器的响应数据,这些数据会放到网络IO管道中。
5、有一个线程持续监听IO管道中收到的数据,一旦拿到数据,就去队列中取出一个Message,把服务器返回的数据写到这个Message的ResultBox中。
给ResultBox赋值完,程序还会通知等待的API继续执行,同步调用是通过线程通信的方式通知,异步调用是通过更新Task的执行结果状态来通知。
最后API从ResultBox中取出数据返回给调用方。
管道技术
无论是同步调用还是异步调用,它们的底层通信方式都统一到了管道技术,这是 StackExchange.Redis 性能出类拔萃的根基,这部分就专门来介绍下。
这里说的管道技术指的是使用System.IO.Pipelines库,这个库提供了一种高效的方式来优化流式数据处理,具备更高的吞吐量、更低的延迟。具体用途:网络上,可以用来构建高性能的TCP或UDP服务器;对于大文件的读写操作,使用Pipelines可以减少内存占用,提高处理速度。
PipeWriter和PipeReader是System.IO.Pipelines中的核心组件,它们用于构建管道处理数据流。这里分享个例子:
using System;
using System.IO.Pipelines;
using System.Text;
using System.Threading.Tasks;
class Program
{
static async Task Main(string[] args)
{
// 创建一个管道
var pipe = new Pipe();
// 启动一个任务来写入数据
var writing = FillPipeAsync(pipe.Writer);
// 启动一个任务来读取数据
var reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
private static async Task FillPipeAsync(PipeWriter writer)
{
for (int i = 0; i < 5; i++)
{
// 写入一些数据到管道中
string message = $"Message {i}";
byte[] messageBytes = Encoding.UTF8.GetBytes(message);
// 将数据写入管道
Memory<byte> memory = writer.GetMemory(messageBytes.Length);
messageBytes.CopyTo(memory);
writer.Advance(messageBytes.Length);
// 通知管道有数据写入
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
// 模拟一些延迟
await Task.Delay(500);
}
// 告诉管道我们已经完成写入
await writer.CompleteAsync();
}
private static async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
// 读取管道中的数据
ReadResult result = await reader.ReadAsync();
var buffer = result.Buffer;
// 处理读取到的数据
foreach (var segment in buffer)
{
string message = Encoding.UTF8.GetString(segment.Span);
Console.WriteLine($"Read: {message}");
}
// 告诉管道我们已经处理了这些数据
reader.AdvanceTo(buffer.End);
// 如果没有更多数据可以读取,退出循环
if (result.IsCompleted)
{
break;
}
}
// 告诉管道我们已经完成读取
await reader.CompleteAsync();
}
}在这个示例中,我们创建了一个 Pipe 对象,并分别启动了两个任务来写入和读取数据:
- FillPipeAsync 方法中,使用 PipeWriter 写入数据到管道。
- ReadPipeAsync 方法中,使用 PipeReader 从管道中读取数据并处理。
通过这种方式,我们可以高效地处理流式数据,同时利用管道的优势来提高吞吐量和降低延迟。
其实在很多的高性能IO库中,使用的都是管道技术,比如Java的NIO、Windows的IOCP、Linux的epoll,本质上都是通过一个类似管道的东西来统筹管理数据传输,减少不必要的调用和检查,达到高效通信的目的。
以上就是本文的主要内容,如有问题,欢迎讨论交流!

StackExchange.Redis 是一个高性能的 Redis 客户端库,主要用于 .NET 环境下与 Redis 服务器进行通信,大名鼎鼎的stackoverflow 网站就使用它。它使用异步编程模型,能够高效处理大量请求。支持 Redis 的绝大部分功能,包括发布/订阅、事务、Lua 脚本等。由 StackExchange 团队维护,质量和更新频率有保障。这篇文章就来给大家分享下 StackExchange.Redis 为什么玩的这么溜。
我将通过分析 StackExchange.Redis 中的同步调用和异步调用逻辑,来给大家一步步揭开它的神秘面纱。
同步API
向Redis发送消息
Redis 客户端的 Get、Set 等操作都会封装成为 Message,操作最终会走到这个方法,我们先大致看下代码:
ConnectionMultiplexer.cs
internal T? ExecuteSyncImpl<T>(Message message, ResultProcessor<T>? processor, ServerEndPoint? server, T? defaultValue = default)
{
...
// 创建一个ResultBox对象,这个对象将会放到Message中用来承载Redis的返回值
var source = SimpleResultBox<T>.Get();
WriteResult result;
// 锁住ResultBox对象,下边会有大用
lock (source)
{
// 将Message发送到Redis服务器
result = TryPushMessageToBridgeSync(message, processor, source, ref server);
...
// 调用 Monitor.Wait 释放对 ResultBox 对象的锁,同时让当前线程停在这里
if (Monitor.Wait(source, TimeoutMilliseconds))
{
Trace("Timely response to " + message);
}
...
}
// 最终从 ResultBox 取出结果
var val = source.GetResult(out var ex, canRecycle: true);
...
return val;
...
}仔细说一下大概的处理逻辑。
- 先构造一个ResultBox对象,用来承载Message的执行结果。
- 然后尝试把这个Message推送到Redis服务器,注意程序内部会把当前Message和ResultBox做一个绑定。
- 等待Redis服务器返回,返回结果赋值到ResultBox对象上。
- 最后从ResultBox对象中取出结果,返回给调用方。
注意这里用到了锁(lock),还使用了Monitor.Wait,这是什么目的呢?
Monitor.Wait 一般和 Monitor.Pulse 搭配使用,用来在线程间通信。
- 调用 Monitor.Wait 时,lock住的ResultBox会被释放,同时当前线程就会挂起,停在这里。
- Redis服务器返回结果后,把结果数据赋值到ResultBox上。
- 其它线程lock住这个ResultBox,调用Monitor.Pulse,之前被挂起的线程继续执行。
通过这种方式,我们就达成了一个跨线程的同步调用效果。
为什么会跨线程呢?直接调用Redis等着返回结果不行吗?
因为 StackExchange.Redis 底层使用了 System.IO.Pipelines 来优化网络IO,这个库采用了生产者/消费者的异步模式来处理网络请求和响应,发送数据和接收数据很可能是在不同的线程中。
以上就是向Redis服务器发送消息的一个宏观理解,但是这里有一个隐藏的问题:
异步情况下怎么把Redis的返回结果和消息对应上?
我们继续跟踪向 Redis 服务器发送 Message 的代码,也就是深入 TryPushMessageToBridgeSync 的内部。
一路跟随,代码会走到这里:
PhysicalBridge.cs
internal WriteResult WriteMessageTakingWriteLockSync(PhysicalConnection physical, Message message)
{
...
bool gotLock = false;
try
{
...
// 获取单写锁,同时只能写一个Message
gotLock = _singleWriterMutex.Wait(0);
if (!gotLock)
{
gotLock = _singleWriterMutex.Wait(TimeoutMilliseconds);
if (!gotLock) return TimedOutBeforeWrite(message);
}
...
// 继续调用内部方法写数据
WriteMessageInsideLock(physical, message);
...
// 刷新网络管道,将数据通过网络发出去
physical.FlushSync(false, TimeoutMilliseconds);
}
catch (Exception ex) { ... }
finally
{
if (gotLock)
{
_singleWriterMutex.Release();
}
}
}这里边用信号量做了一个锁,保证同时只有一个写操作。
那么为什么要保证同时只能一个写操作呢?
我们继续跟踪代码:
private WriteResult WriteMessageToServerInsideWriteLock(PhysicalConnection connection, Message message)
{
...
// 把消息添加到队列
connection.EnqueueInsideWriteLock(message);
// 把消息写到网络接口
message.WriteTo(connection);
...
}这里有两个操作,一是将Message添加到队列,二是向网络接口写数据。
保证同时只有一个写操作,或者加锁的目的,就是让它俩一起完成,能对应起来,不会错乱。
那么我们还要继续问:写队列和写网络对应起来有什么用?
这个问题不好回答,我们先来看看这两个操作都是干什么用的?
为什么要把Message写入队列?
同步IO可以直接拿到当前消息的返回结果,但是 System.IO.Pipelines 底层是异步操作,当处理结果从Redis返回时,我们需要把它对应到一个Messge上。加入队列就是为了方便找到对应的消息。至于为什么用队列,而不用集合,因为队列能够很好的满足这个需求,下边会有说明。
写队列代码在这里:
PhysicalConnection.cs
internal void EnqueueInsideWriteLock(Message next)
{
...
bool wasEmpty;
lock (_writtenAwaitingResponse)
{
...
_writtenAwaitingResponse.Enqueue(next);
}
...
}入队列需要先加锁,因为可能是多线程环境下操作,Queue自身不是线程安全的。
再看一下把消息写到网络接口,这个的目的就是把消息发送到Redis服务器,看一下代码:
PhysicalConnection.cs
internal static void WriteUnifiedPrefixedString(PipeWriter? maybeNullWriter, byte[]? prefix, string? value)
{
...
// writer 就是管道的写入接口
var span = writer.GetSpan(3 + Format.MaxInt32TextLen);
span[0] = (byte)'$';
int bytes = WriteRaw(span, totalLength, offset: 1);
writer.Advance(bytes);
if (prefixLength != 0) writer.Write(prefix);
if (encodedLength != 0) WriteRaw(writer, value, encodedLength);
WriteCrlf(writer);
...
}源码最底层是通过 System.IO.Pipelines 中的 PipeWriter 把 Message 命令发送到Redis服务器的,这段代码比较复杂,大家先大概知道做什么用的就行了。
到此,向Redis发送消息就处理完成了。
现在我们已经大概了解向Redis服务器发送消息的过程:在最上层通过Monitor模拟了同步操作,在最底层使用了高效的异步IO,为了适配同步和异步,写操作内含了两个子操作:写队列和写网络。
但是我们仍然不能回答一个问题:写队列和写网络为什么要放到一个锁中执行?或者说为什么要保证同时只能一个写操作?
要回答这个问题,我们还得继续看程序对Redis响应结果的处理。
处理Redis响应结果
Redis 客户端与 Redis 服务器建立连接时,会创建一个死循环,持续的从 System.IO.Pipelines 的管道中读取Redis 服务器返回的消息,并进行相应的处理。最上层方法就是这个 ReadFromPipe:
PhysicalConnection.cs
private async Task ReadFromPipe()
{
...
while (true)
{
...
// 没有新数据从Redis服务器返回时,ReadAsync会等在这里
readResult = await input.ReadAsync().ForAwait();
...
var buffer = readResult.Buffer;
...
if (!buffer.IsEmpty)
{
// 这里边解析数据,并赋值到相关对象上
handled = ProcessBuffer(ref buffer);
}
}
}对返回数据的处理重点在这个 ProcessBuffer 方法中。它会先对数据进行一个简单的解析,然后再调用 MatchResult,从字面义上看就是匹配结果,匹配到那个结果呢?
private int ProcessBuffer(ref ReadOnlySequence<byte> buffer)
{
...
var reader = new BufferReader(buffer);
var result = TryParseResult(_protocol >= RedisProtocol.Resp3, _arena, in buffer, ref reader, IncludeDetailInExceptions, this);
...
MatchResult(result);
...
}还记得我们在上边向Redis发送Message前,先创建了一个 ResultBox 对象,匹配的就是它。
怎么找到对应的 ResultBox 对象呢?
看下边的代码,程序从队列中取出了一个Message 实例,就是要匹配到这个 Message 实例关联的ResultBox。
private void MatchResult(in RawResult result)
{
...
// 从队列中取出最早的一条Redis操作消息
lock (_writtenAwaitingResponse)
{
if (!_writtenAwaitingResponse.TryDequeue(out msg))
{
throw new InvalidOperationException("Received response with no message waiting: " + result.ToString());
}
}
...
// 将Redis返回的结果设置到取出的消息中
if (msg.ComputeResult(this, result))
{
_readStatus = msg.ResultBoxIsAsync ? ReadStatus.CompletePendingMessageAsync : ReadStatus.CompletePendingMessageSync;
// 完成Redis操作
msg.Complete();
}
...
}为什么从队列取出的 Message 就一定能对应到 Redis 服务器当前返回的结果呢?
要破案了,还记得上边的那个未解问题吗:为什么要保证同时只能一个写操作?
我们每次操作Redis都是:先把Message压入队列,然后再发送到Redis服务器,这两个操作紧密的绑定在一起;而Redis服务器是单线程顺序处理的,最先返回的就是最早压入队列的。加上每次只有一个写操作的控制,我们就能保证最先写入队列的(也就是最先发到Redis服务器的)Message,就能对应到最先从Redis服务器返回的数据。
上面这段程序中的 msg.ComputeResult 就是用来将 Redis 最新返回的数据赋值到最新从队列中拿出来的 Message 实例中。
现在 Message 实例 已经获取到了 Redis返回结果,还记得之前的发送线程一直在挂起等待吗?
下边的 msg.Complete 就是来让发送线程恢复执行的,看这个代码 :
Message.cs(Message)
public void Complete()
{
...
// ResultBox激活继续处理
currBox?.ActivateContinuations();
}还有一层封装,继续看这个代码:
ResultBox.cs(SimpleResultBox)。
void IResultBox.ActivateContinuations()
{
lock (this)
{
// 通知等待Redis响应的线程,Redis返回结果了,请继续你的表演
Monitor.PulseAll(this);
}
...
}Monitor.PulseAll 一出,发送线程立马恢复执行,向调用方返回执行结果。
一次同步调用就这样完成了。
异步API
异步API和同步API使用相同的通信底层,包括写队列和写网络管道的处理,只是在处理返回值的方式上存在不同。大家可以看一下异步和同步调试堆栈的对比图:
执行到 PhysicalBridge.WriteMessageInsideLock 这一步时处理就同步了。这一步的代码上边也贴过了,这里再给大家看看:其中的主要逻辑就是写队列和写网络管道。
private WriteResult WriteMessageToServerInsideWriteLock(PhysicalConnection connection, Message message)
{
...
// 把消息添加到队列
connection.EnqueueInsideWriteLock(message);
// 把消息写到网络接口
message.WriteTo(connection);
...
}向Redis发送消息
我们再简单看看异步API中是如何发送消息的,看代码:
internal Task<T?> ExecuteAsyncImpl<T>(Message? message, ResultProcessor<T>? processor, object? state, ServerEndPoint? server)
{
...
// 创建一个Task执行状态跟踪对象
TaskCompletionSource<T?>? tcs = null;
// 创建一个ResultBox对象,这个对象将会放到Message中用来承载Redis的返回值
// 异步这里特别将 ResultBox 和 TaskCompletionSource 绑定到了一起
// 获取到Redis服务器返回的数据后,TaskCompletionSource 的执行状态将被更新为完成
IResultBox<T?>? source = null;
if (!message.IsFireAndForget)
{
source = TaskResultBox<T?>.Create(out tcs, state);
}
// 将Message消息发送到 Redis服务器
var write = TryPushMessageToBridgeAsync(message, processor, source!, ref server);
...
// 返回Task,调用方可以 await
return tcs.Task;
}相比同步API,这里多创建了一个 TaskCompletionSource 的实例,它用来跟踪异步任务的执行状态,程序会在接收到Redis服务器的返回数据时,将 TaskCompletionSource 的状态更新为完成执行。
里边的代码我就不展开讲了,大家有兴趣的可以按照上方我截图的调用堆栈去跟踪下。
处理Redis响应结果
异步API和同步API使用同一个死循环方法:ReadFromPipe,程序启动时也只有这一个死循环在运行。
代码上边都讲过了,这里只说下最后“ResultBox激活继续处理”的部分,这个 ResultBox 和同步调用的 ResultBox 略有不同,看代码:
void IResultBox.ActivateContinuations()
{
...
ActivateContinuationsImpl();
}
private void ActivateContinuationsImpl()
{
var val = _value;
...
TrySetResult(val);
...
}
public bool TrySetResult(TResult result)
{
// 设置异步任务执行完成
bool rval = _task.TrySetResult(result);
...
return rval;
}最重要的就是 _task.TrySetResult 这句,这里的 _task 就是发起异步调用时创建的 TaskCompletionSource 实例,TrySetResult 的作用就是设置异步任务执行完成,对应的 await 代码就可以继续向下执行了。
await client.SetAsync("hello", "fireflysoft.net");
// 继续执行下边的代码
...总结
总体执行逻辑
通过对同步API、异步API的执行逻辑分析,我这里总结了一张图,可以让大家快速的理清其中的处理逻辑。
我再用文字描述下这个执行逻辑:
1、无论是同步调用还是异步调用,StackExchange.Redis 底层都是先会创建一个 Message 对象;每个 Message 对象都会关联一个ResultBox对象(同步和异步调用对应的ResultBox对象略有不同),这个对象用来承载Redis执行结果;
2、然后程序会把Message存入队列、发送到网络IO管道,写队列和写网络IO放到了一个互斥锁中,同时只有一个Message写入,这是为了保证收到Redis响应时正好对应队列中的第一条数据。
执行完这些操作后,API会等待,但是同步调用和异步调用等待的方式不同,同步会挂起线程等待其它线程同步结果,异步会使用await等待Task执行结果;
3、Redis 命令被发送到网络,抵达Redis服务器
4、接收到Redis服务器的响应数据,这些数据会放到网络IO管道中。
5、有一个线程持续监听IO管道中收到的数据,一旦拿到数据,就去队列中取出一个Message,把服务器返回的数据写到这个Message的ResultBox中。
给ResultBox赋值完,程序还会通知等待的API继续执行,同步调用是通过线程通信的方式通知,异步调用是通过更新Task的执行结果状态来通知。
最后API从ResultBox中取出数据返回给调用方。
管道技术
无论是同步调用还是异步调用,它们的底层通信方式都统一到了管道技术,这是 StackExchange.Redis 性能出类拔萃的根基,这部分就专门来介绍下。
这里说的管道技术指的是使用System.IO.Pipelines库,这个库提供了一种高效的方式来优化流式数据处理,具备更高的吞吐量、更低的延迟。具体用途:网络上,可以用来构建高性能的TCP或UDP服务器;对于大文件的读写操作,使用Pipelines可以减少内存占用,提高处理速度。
PipeWriter和PipeReader是System.IO.Pipelines中的核心组件,它们用于构建管道处理数据流。这里分享个例子:
using System;
using System.IO.Pipelines;
using System.Text;
using System.Threading.Tasks;
class Program
{
static async Task Main(string[] args)
{
// 创建一个管道
var pipe = new Pipe();
// 启动一个任务来写入数据
var writing = FillPipeAsync(pipe.Writer);
// 启动一个任务来读取数据
var reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
private static async Task FillPipeAsync(PipeWriter writer)
{
for (int i = 0; i < 5; i++)
{
// 写入一些数据到管道中
string message = $"Message {i}";
byte[] messageBytes = Encoding.UTF8.GetBytes(message);
// 将数据写入管道
Memory<byte> memory = writer.GetMemory(messageBytes.Length);
messageBytes.CopyTo(memory);
writer.Advance(messageBytes.Length);
// 通知管道有数据写入
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
// 模拟一些延迟
await Task.Delay(500);
}
// 告诉管道我们已经完成写入
await writer.CompleteAsync();
}
private static async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
// 读取管道中的数据
ReadResult result = await reader.ReadAsync();
var buffer = result.Buffer;
// 处理读取到的数据
foreach (var segment in buffer)
{
string message = Encoding.UTF8.GetString(segment.Span);
Console.WriteLine($"Read: {message}");
}
// 告诉管道我们已经处理了这些数据
reader.AdvanceTo(buffer.End);
// 如果没有更多数据可以读取,退出循环
if (result.IsCompleted)
{
break;
}
}
// 告诉管道我们已经完成读取
await reader.CompleteAsync();
}
}在这个示例中,我们创建了一个 Pipe 对象,并分别启动了两个任务来写入和读取数据:
- FillPipeAsync 方法中,使用 PipeWriter 写入数据到管道。
- ReadPipeAsync 方法中,使用 PipeReader 从管道中读取数据并处理。
通过这种方式,我们可以高效地处理流式数据,同时利用管道的优势来提高吞吐量和降低延迟。
其实在很多的高性能IO库中,使用的都是管道技术,比如Java的NIO、Windows的IOCP、Linux的epoll,本质上都是通过一个类似管道的东西来统筹管理数据传输,减少不必要的调用和检查,达到高效通信的目的。
以上就是本文的主要内容,如有问题,欢迎讨论交流!